Rds Mysql Read Replica Not Clearing Temp
Introduction
MySQL and PostgreSQL-compatible relational database built for the cloud. Performance and availability of commercial-grade databases at 1/10th the price.
Amazon Aurora
User Guide for Aurora
Amazon Aurora is a MySQL and PostgreSQL-compatible relational database congenital for the deject, that combines the performance and availability of traditional enterprise databases with the simplicity and toll-effectiveness of open up source databases.
Amazon Aurora is upwards to five times faster than standard MySQL databases and 3 times faster than standard PostgreSQL databases. It provides the security, availability, and reliability of commercial databases at 1/10th the cost. Amazon Aurora is fully managed by Amazon Relational Database Service (RDS), which automates fourth dimension-consuming administration tasks like hardware provisioning, database setup, patching, and backups.
Amazon Aurora features a distributed, error-tolerant, self-healing storage system that motorcar-scales up to 128TB per database instance. It delivers high performance and availability with up to 15 depression-latency read replicas, indicate-in-time recovery, continuous fill-in to Amazon S3, and replication across three Availability Zones (AZs).
Visit the Amazon RDS Management Console to create your get-go Aurora database example and start migrating your MySQL and PostgreSQL databases.
- Functioning
- CPU
- Memory
- Storage
- IOPS
- Manageability
- Security
- Access Command
- Encryption
- Availability and Durability
- Automated Backup
- Transmission Snapshot
- Multi-AZs
- Read Replica
- Diaster Recovery
- Migration
- Monitoring
Amazon Aurora connection management
Amazon Aurora connection management
Types of Aurora endpoints
- Cluster endpoint: A cluster endpoint (or writer endpoint) for an Aurora DB cluster connects to the current primary DB case for that DB cluster. Each Aurora DB cluster has one cluster endpoint and i main DB instance. Cluster endpoint is the only endpoint has write chapters.
-
mydbcluster.cluster-123456789012.us-due east-one.rds.amazonaws.com:3306
-
- Reader endpoint: A reader endpoint for an Aurora DB cluster provides load-balancing support for read-just connections to the DB cluster. Each Aurora DB cluster has i reader endpoint. If the cluster contains one or more Aurora Replicas, the reader endpoint load-balances each connexion request amidst the Aurora Replicas. The reader endpoint load-balances connections to available Aurora Replicas in an Aurora DB cluster. Information technology doesn't load-balance individual queries. If you want to load-balance each query to distribute the read workload for a DB cluster, open a new connection to the reader endpoint for each query. If your cluster contains only a primary instance and no Aurora Replicas, the reader endpoint connects to the primary instance. In that case, you tin can perform write operations through this endpoint.
-
mydbcluster.cluster-ro-123456789012.us-east-i.rds.amazonaws.com:3306
-
- Custom endpoint: A custom endpoint for an Aurora cluster represents a set of DB instances that you lot choose.
-
myendpoint.cluster-custom-123456789012.us-eastward-1.rds.amazonaws.com:3306
-
- Instance endpoint: An example endpoint connects to a specific DB case within an Aurora cluster. The case endpoint provides direct control over connections to the DB cluster, for scenarios where using the cluster endpoint or reader endpoint might not be appropriate. For case, your customer application might crave more fine-grained load balancing based on workload type. In this case, you can configure multiple clients to connect to different Aurora Replicas in a DB cluster to distribute read workloads.
-
mydbinstance.123456789012.us-eastward-1.rds.amazonaws.com:3306
-
Functioning
Managing Amazon Aurora MySQL
Managing Amazon Aurora MySQL
Managing operation and scaling for Amazon Aurora MySQL
Managing performance and scaling for Amazon Aurora MySQL
| Case course | max_connections default value |
|---|---|
| db.t2.small | 45 |
| db.t2.medium | 90 |
| db.t3.small | 45 |
| db.t3.medium | 90 |
| db.r3.large | 1000 |
| db.r3.xlarge | 2000 |
| db.r3.2xlarge | 3000 |
| db.r3.4xlarge | 4000 |
| db.r3.8xlarge | 5000 |
| db.r4.large | 1000 |
| db.r4.xlarge | 2000 |
| db.r4.2xlarge | 3000 |
| db.r4.4xlarge | 4000 |
| db.r4.8xlarge | 5000 |
| db.r4.16xlarge | 6000 |
| db.r5.large | 1000 |
| db.r5.xlarge | 2000 |
| db.r5.2xlarge | 3000 |
| db.r5.4xlarge | 4000 |
| db.r5.8xlarge | 5000 |
| db.r5.12xlarge | 6000 |
| db.r5.16xlarge | 6000 |
| db.r5.24xlarge | 7000 |
Resize Node
Service -> RDS -> Databases
Select one node of your aurora cluster and so click on Modify
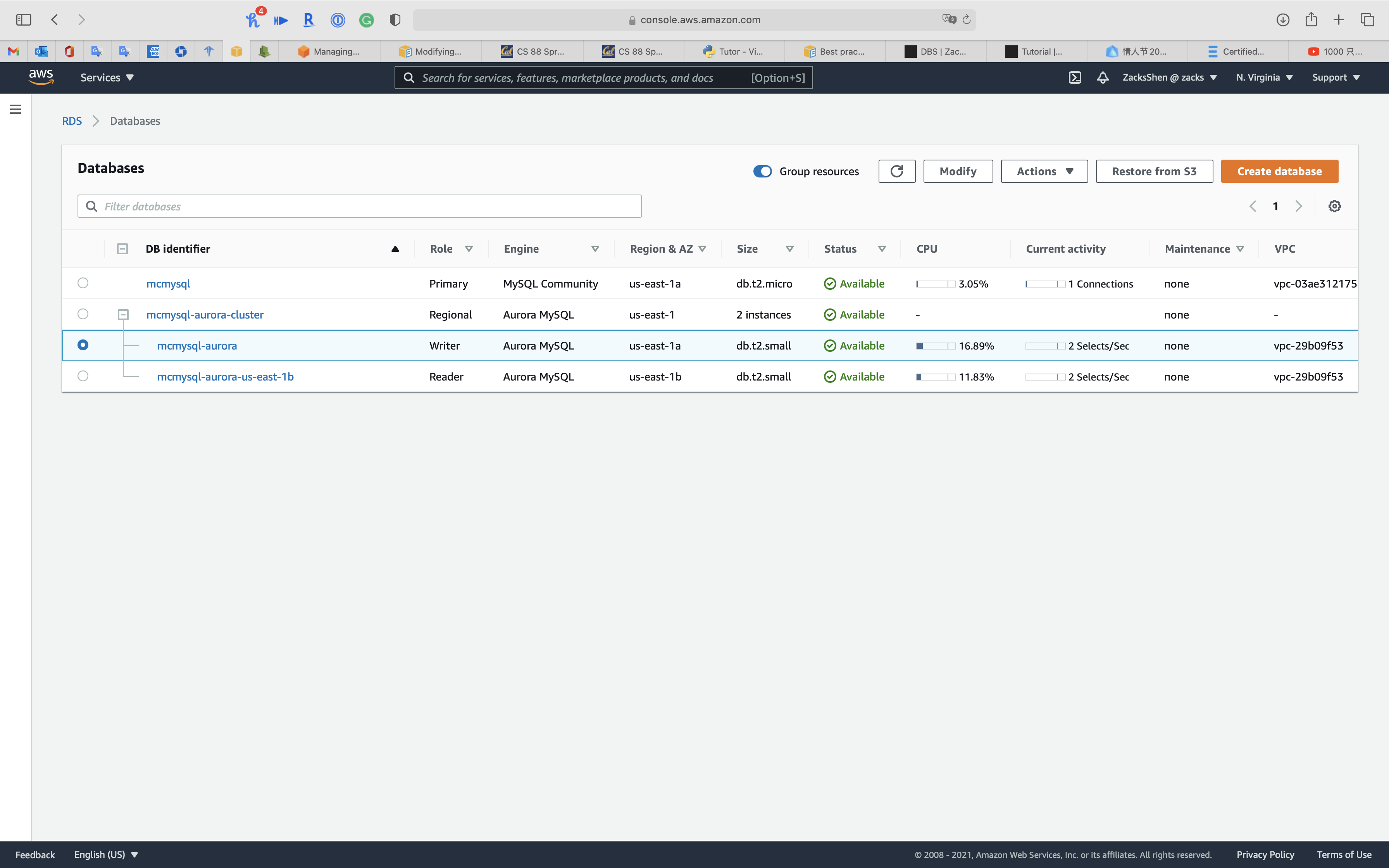
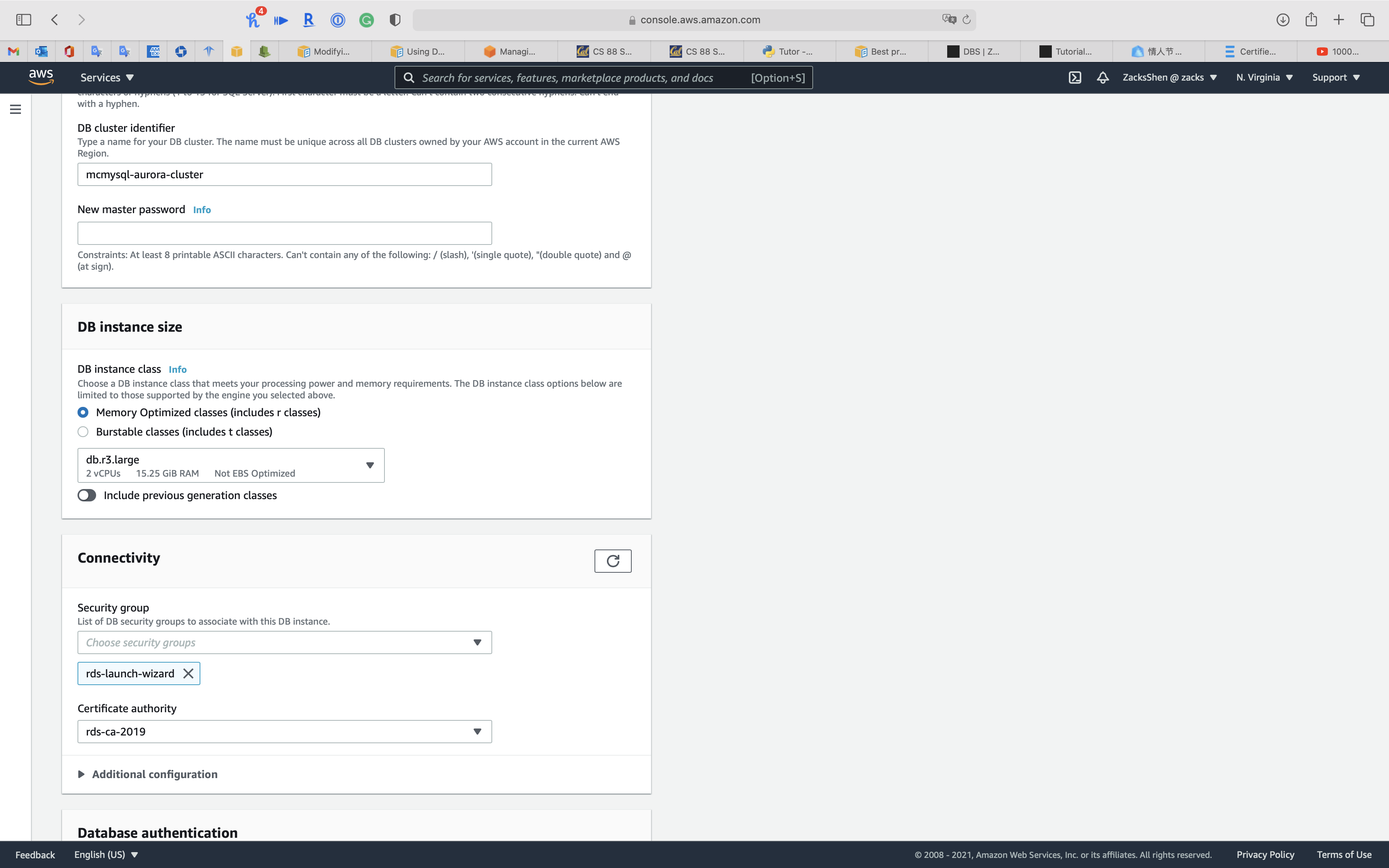
Under DB instance size
Select Retention Optimized classes (includes r classes) for powerful use example. Too, t series does non support Database Activity Streams through Kinesis
Select db.r3.large
Click on Keep
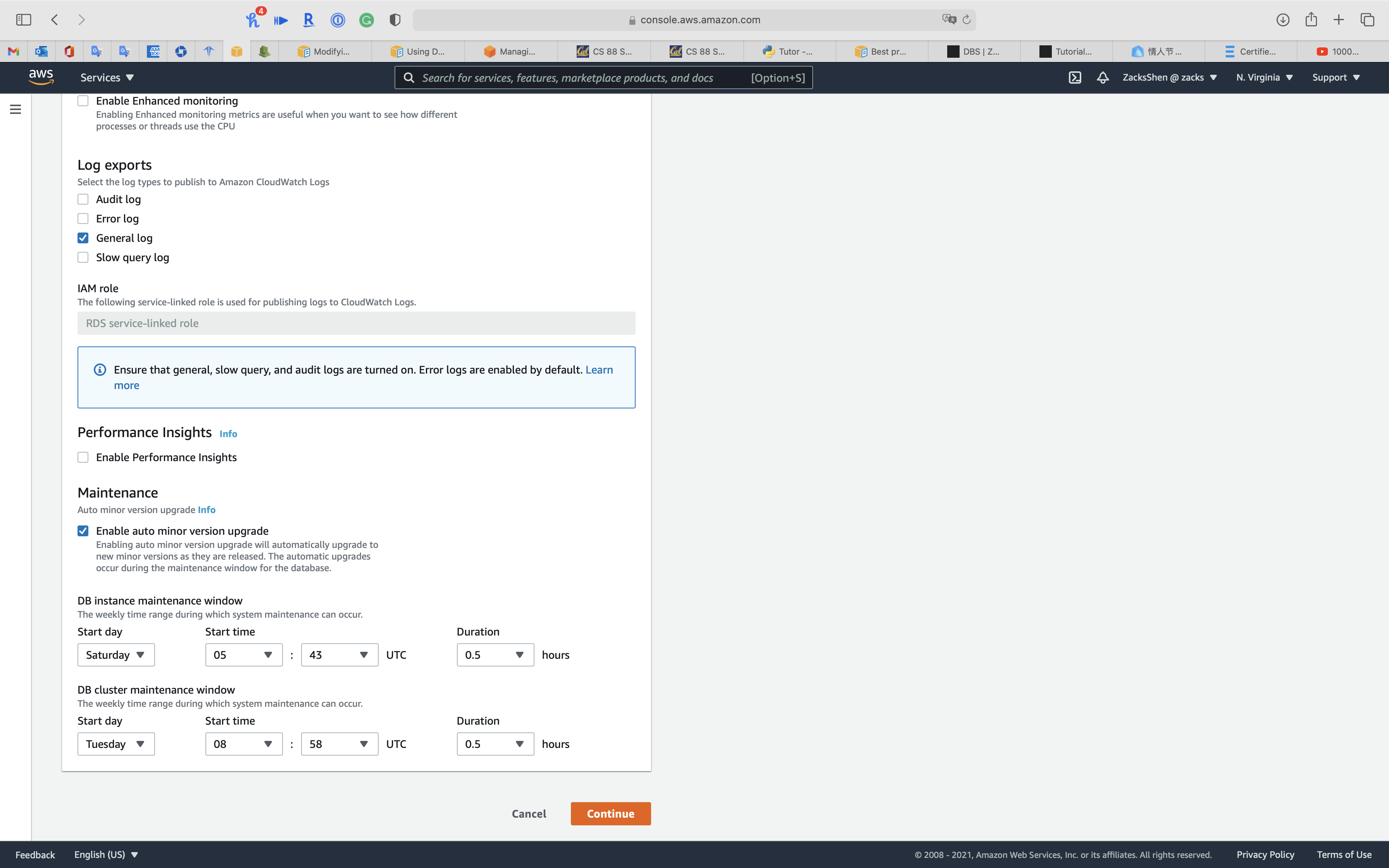
Select Apply immediately
Click on Modify DB instance
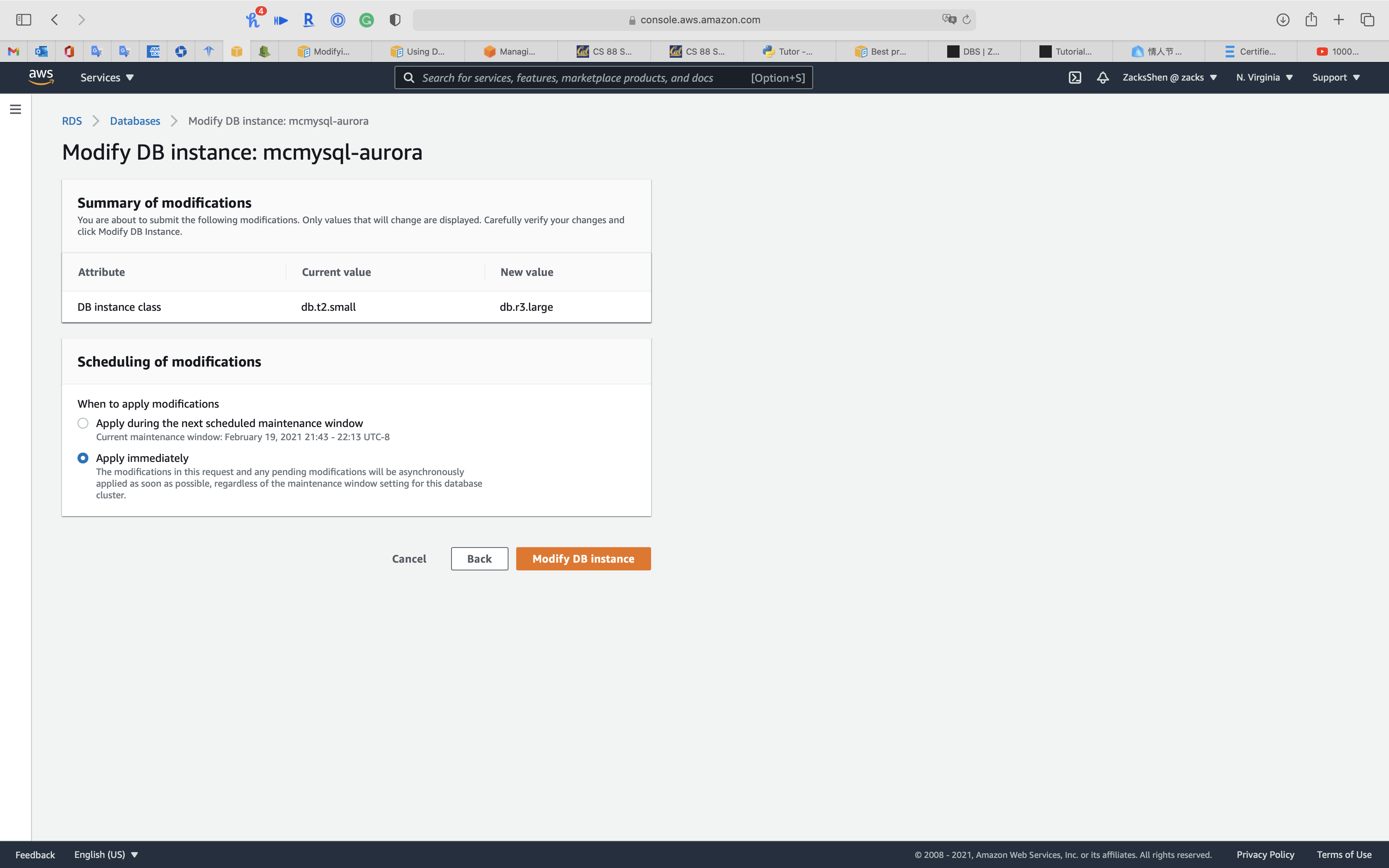
Manageability
Managing Aurora DB Cluster
Managing an Amazon Aurora DB cluster
Cloning an Aurora DB cluster book
Cloning an Aurora DB cluster volume
Using the Aurora cloning feature, you can quickly and toll-effectively create a new cluster containing a duplicate of an Aurora cluster volume and all its data. We refer to the new cluster and its associated cluster volume every bit a clone. Creating a clone is faster and more infinite-efficient than physically copying the data using a dissimilar technique such every bit restoring a snapshot.
Managing Amazon Aurora MySQL
Managing Amazon Aurora MySQL
Testing Amazon Aurora using fault injection queries
Testing Amazon Aurora using error injection queries
You can exam the mistake tolerance of your Amazon Aurora DB cluster by using fault injection queries. Fault injection queries are issued every bit SQL commands to an Amazon Aurora instance and they enable y'all to schedule a faux occurrence of i of the following events:
- A crash of a author or reader DB instance
- A failure of an Aurora Replica
- A disk failure
- Deejay congestion
When a fault injection query specifies a crash, it forces a crash of the Aurora DB instance. The other error injection queries consequence in simulations of failure events, just don't cause the event to occur. When you submit a mistake injection query, yous also specify an amount of time for the failure upshot simulation to occur for.
You lot can submit a fault injection query to one of your Aurora Replica instances by connecting to the endpoint for the Aurora Replica. For more data, encounter Amazon Aurora connection management.
Backtracking an Aurora DB cluster
Backtracking an Aurora DB cluster
With Amazon Aurora with MySQL compatibility, you lot can backtrack a DB cluster to a specific time, without restoring data from a backup.
Overview of backtracking
Backtracking "rewinds" the DB cluster to the time yous specify. Backtracking is not a replacement for backing upwards your DB cluster and so that you can restore it to a betoken in time. Notwithstanding, backtracking provides the post-obit advantages over traditional backup and restore:
- Yous tin can easily disengage mistakes. If you mistakenly perform a subversive action, such equally a DELETE without a WHERE clause, you tin backtrack the DB cluster to a fourth dimension before the subversive action with minimal intermission of service.
- You tin backtrack a DB cluster speedily. Restoring a DB cluster to a point in time launches a new DB cluster and restores information technology from backup data or a DB cluster snapshot, which can have hours. Backtracking a DB cluster doesn't crave a new DB cluster and rewinds the DB cluster in minutes.
- You tin explore earlier data changes. You can repeatedly backtrack a DB cluster back and forth in fourth dimension to aid determine when a detail data modify occurred. For example, y'all can backtrack a DB cluster three hours and and so backtrack forward in fourth dimension 1 hour. In this case, the backtrack time is two hours before the original fourth dimension.
Cron job
Schedule jobs for Amazon RDS and Aurora PostgreSQL using Lambda and Secrets Manager
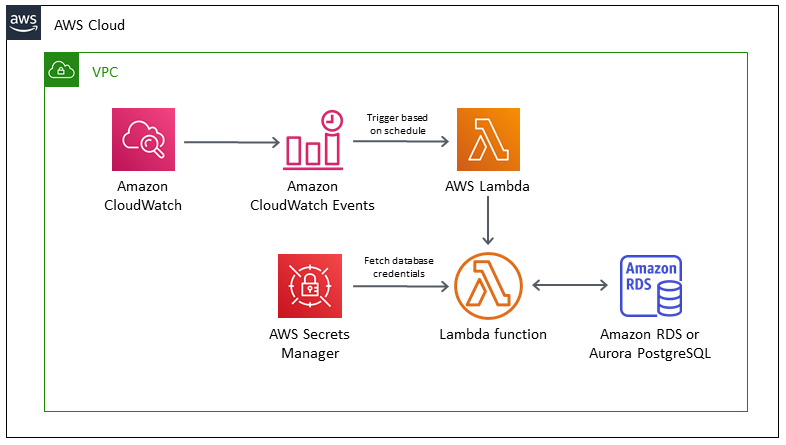
Security
Admission Control
You tin cosign to your DB cluster using AWS IAM database authentication. With this authentication method, y'all don't need to use a password when you connect to a DB cluster. Instead, you utilise an authentication token that expires 15 minutes after creation.
- Enable IAM database authentication on the Aurora cluster.
- Create a database user for each team member without a password.
- Attach an IAM policy to each administrator's IAM user business relationship that grants the connect privilege using their database user account.
Encryption
SSL/TLS
Using SSL/TLS to encrypt a connexion to a DB cluster
Security with Amazon Aurora MySQL
Using SSL/TLS to encrypt a connection to a DB cluster
Amazon Virtual Private Cloud VPCs and Amazon Aurora
Updating applications to connect to Aurora MySQL DB clusters using new SSL/TLS certificates
How do I troubleshoot issues connecting to Amazon Aurora?
How Does SSL Work? | SSL Certificates and TLS
When the require_secure_transport parameter is set to ON for a DB cluster, a database customer tin can connect to it if it can plant an encrypted connexion. Otherwise, an error message similar to the following is returned to the client:
1 | MySQL Error 3159 (HY000): Connections using insecure transport are prohibited while --require_secure_transport=ON. |
To get a root certificate that works for all AWS Regions, excluding opt-in AWS Regions, download it from https://s3.amazonaws.com/rds-downloads/rds-ca-2019-root.pem
This root certificate is a trusted root entity and should work in virtually cases but might fail if your application doesn't accept document chains. If your awarding doesn't accept document chains, download the AWS Region–specific document from the list of intermediate certificates found later in this section.
To get a certificate bundle that contains both the intermediate and root certificates, download from https://s3.amazonaws.com/rds-downloads/rds-combined-ca-package.pem
If your application is on Microsoft Windows and requires a PKCS7 file, y'all tin can download the PKCS7 certificate bundle. This parcel contains both the intermediate and root certificates at https://s3.amazonaws.com/rds-downloads/rds-combined-ca-packet.p7b
How does SSL/TLS work?
These are the essential principles to grasp for understanding how SSL/TLS works:
- Secure advice begins with a TLS handshake, in which the two communicating parties open up a secure connectedness and exchange the public key
- During the TLS handshake, the two parties generate session keys, and the session keys encrypt and decrypt all communications afterward the TLS handshake
- Dissimilar session keys are used to encrypt communications in each new session
- TLS ensures that the political party on the server side, or the website the user is interacting with, is actually who they claim to exist
- TLS likewise ensures that data has non been altered, since a message hallmark code (MAC) is included with transmissions
Symmetric encryption with session keys
Unlike asymmetric encryption, in symmetric encryption the two parties in a conversation utilise the same key. Later the TLS handshake, both sides use the same session keys for encryption. Once session keys are in use, the public and private keys are not used anymore. Session keys are temporary keys that are non used again one time the session is terminated. A new, random set of session keys will be created for the next session.

What is an SSL certificate?
An SSL certificate is a file installed on a website'southward origin server. It'southward simply a data file containing the public key and the identity of the website possessor, along with other information. Without an SSL certificate, a website'due south traffic tin can't be encrypted with TLS.
Technically, any website owner can create their ain SSL certificate, and such certificates are chosen self-signed certificates. Nevertheless, browsers do non consider self-signed certificates to exist equally trustworthy as SSL certificates issued past a certificate authority.
How does a website get an SSL certificate?
Website owners need to obtain an SSL certificate from a document authority, so install it on their web server (often a web host tin handle this process). A document dominance is an outside party who can confirm that the website owner is who they say they are. They keep a copy of the certificates they effect.
Availability and Durability
Automated Fill-in
Transmission Snapshot
Multi-AZs
Read Replica & Failover
Overview
Customizable failover order for Amazon Aurora read replicas
Managing an Amazon Aurora DB cluster
Loftier availability for Amazon Aurora
Calculation Aurora replicas to a DB cluster
Customizable failover social club for Amazon Aurora read replicas
Amazon Aurora at present allows you to assign a promotion priority tier to each example on your database cluster. The priority tiers give you more control over replica promotion during failovers. When the chief instance fails, Amazon RDS volition promote the replica with the highest priority to chief. Yous can assign lower priority tiers to replicas that you don't want promoted to the primary instance.
High availability for Aurora DB instances
For a cluster using single-principal replication, afterward you lot create the principal example, you tin can create up to fifteen read-only Aurora Replicas. The Aurora Replicas are besides known every bit reader instances.
During day-to-day operations, yous tin can offload some of the work for read-intensive applications by using the reader instances to procedure SELECT queries. When a problem affects the primary case, one of these reader instances takes over as the main case. This mechanism is known as failover.
Loftier availability across AWS Regions with Aurora global databases
For high availability across multiple AWS Regions, you tin can set upwards Aurora global databases. Each Aurora global database spans multiple AWS Regions, enabling low latency global reads and disaster recovery from outages across an AWS Region. Aurora automatically handles replicating all data and updates from the primary AWS Region to each of the secondary Regions.
Fault tolerance for an Aurora DB cluster
An Aurora DB cluster is fault tolerant past design. The cluster book spans multiple Availability Zones in a unmarried AWS Region, and each Availability Zone contains a copy of the cluster volume data. This functionality means that your DB cluster can tolerate a failure of an Availability Zone without any loss of information and but a cursory pause of service.
If the chief instance in a DB cluster using single-master replication fails, Aurora automatically fails over to a new main instance in one of two means:
- By promoting an existing Aurora Replica to the new primary case
- By creating a new primary example
If the DB cluster has one or more Aurora Replicas, and so an Aurora Replica is promoted to the primary case during a failure outcome. A failure event results in a brief suspension, during which read and write operations fail with an exception. However, service is typically restored in less than 120 seconds, and ofttimes less than sixty seconds. To increment the availability of your DB cluster, we recommend that you lot create at least one or more than Aurora Replicas in 2 or more different Availability Zones.
You can customize the order in which your Aurora Replicas are promoted to the primary instance afterward a failure by assigning each replica a priority. Priorities range from 0 for the starting time priority to xv for the last priority. If the primary case fails, Amazon RDS promotes the Aurora Replica with the improve priority to the new chief case. You lot tin modify the priority of an Aurora Replica at any time. Modifying the priority doesn't trigger a failover.
More i Aurora Replica tin can share the same priority, resulting in promotion tiers. If two or more than Aurora Replicas share the same priority, then Amazon RDS promotes the replica that is largest in size. If ii or more Aurora Replicas share the same priority and size, then Amazon RDS promotes an arbitrary replica in the same promotion tier.
If the DB cluster doesn't contain any Aurora Replicas, then the primary instance is recreated during a failure event. A failure effect results in an interruption during which read and write operations fail with an exception. Service is restored when the new primary instance is created, which typically takes less than 10 minutes. Promoting an Aurora Replica to the primary instance is much faster than creating a new primary instance.
Suppose that the master instance in your cluster is unavailable because of an outage that affects an unabridged AZ. In this example, the style to bring a new principal example online depends on whether your cluster uses a multi-AZ configuration. If the cluster contains any reader instances in other AZs, Aurora uses the failover mechanism to promote 1 of those reader instances to be the new chief instance. If your provisioned cluster but contains a single DB instance, or if the primary case and all reader instances are in the aforementioned AZ, you must manually create one or more new DB instances in another AZ. If your cluster uses Aurora Serverless, Aurora automatically creates a new DB example in some other AZ. However, this process involves a host replacement and thus takes longer than a failover.
Adding Aurora replicas to a DB cluster
An Aurora DB cluster with single-chief replication has one principal DB instance and up to xv Aurora Replicas. The main DB instance supports read and write operations, and performs all information modifications to the cluster volume. Aurora Replicas connect to the aforementioned storage book as the primary DB instance, but back up read operations only. You apply Aurora Replicas to offload read workloads from the master DB instance.
- Priority: Choose a failover priority for the instance. If you don't select a value, the default is tier-1. This priority determines the order in which Aurora Replicas are promoted when recovering from a primary case failure.
Fast recovery afterward failover with cluster cache direction for Aurora PostgreSQL
Fast recovery after failover with cluster cache direction for Aurora PostgreSQL
For fast recovery of the writer DB case in your Aurora PostgreSQL clusters if there's a failover, apply cluster cache management for Amazon Aurora PostgreSQL. Cluster cache management ensures that application performance is maintained if there's a failover.
In a typical failover situation, you might see a temporary just big performance degradation after failover. This degradation occurs considering when the failover DB case starts, the buffer cache is empty. An empty cache is besides known equally a cold cache. A cold cache degrades performance because the DB example has to read from the slower disk, instead of taking advantage of values stored in the buffer cache.
With cluster cache management, y'all ready a specific reader DB instance as the failover target. Cluster cache management ensures that the data in the designated reader's enshroud is kept synchronized with the data in the writer DB example's enshroud. The designated reader'due south cache with prefilled values is known every bit a warm cache. If a failover occurs, the designated reader uses values in its warm cache immediately when it'southward promoted to the new writer DB instance. This approach provides your awarding much improve recovery performance.
Cluster cache management requires that the designated reader case have the same instance class type and size (db.r5.2xlarge or db.r5.xlarge, for instance) as the writer. Keep this in listen when you lot create your Aurora PostgreSQL DB clusters so that your cluster tin recover during a failover. For a listing of instance grade types and sizes, come across Hardware specifications for DB instance classes for Aurora.
For more data, see Fast recovery later on failover with cluster cache direction for Aurora PostgreSQL
Key steps:
- Enabling cluster enshroud management: Fix the value of the
apg_ccm_enabledcluster parameter to ane. - For the writer DB instance: choose tier-0 for the Failover priority.
- For one reader DB example: choose tier-0 for the Failover priority.
Diaster Recovery
RTO & RPO
Disaster Recovery (DR) Objectives
Program for Disaster Recovery (DR)
Implementing a disaster recovery strategy with Amazon RDS
| Feature | RTO | RPO | Cost | Scope |
|---|---|---|---|---|
| Automated backups(in one case a mean solar day) | Good | Better | Low | Single Region |
| Manual snapshots | Better | Good | Medium | Cross-Region |
| Read replicas | Best | Best | High | Cross-Region |
In addition to availability objectives, your resiliency strategy should also include Disaster Recovery (DR) objectives based on strategies to recover your workload in example of a disaster event. Disaster Recovery focuses on one-fourth dimension recovery objectives in response natural disasters, large-scale technical failures, or human threats such as set on or fault. This is different than availability which measures mean resiliency over a flow of time in response to component failures, load spikes, or software bugs.
Define recovery objectives for downtime and data loss: The workload has a recovery time objective (RTO) and recovery bespeak objective (RPO).
- Recovery Fourth dimension Objective (RTO) is defined by the organization. RTO is the maximum adequate delay between the intermission of service and restoration of service. This determines what is considered an acceptable time window when service is unavailable.
- Recovery Point Objective (RPO) is defined by the organisation. RPO is the maximum acceptable corporeality of time since the final data recovery point. This determines what is considered an acceptable loss of information between the terminal recovery point and the break of service.

Recovery Strategies
Use defined recovery strategies to meet the recovery objectives: A disaster recovery (DR) strategy has been defined to meet objectives. Cull a strategy such as: backup and restore, agile/passive (pilot light or warm standby), or active/agile.
When architecting a multi-region disaster recovery strategy for your workload, you should choose i of the following multi-region strategies. They are listed in increasing lodge of complexity, and decreasing order of RTO and RPO. DR Region refers to an AWS Region other than the one principal used for your workload (or any AWS Region if your workload is on premises).
- Backup and restore (RPO in hours, RTO in 24 hours or less): Back up your data and applications using point-in-time backups into the DR Region. Restore this data when necessary to recover from a disaster.
- Pilot lite (RPO in minutes, RTO in hours): Replicate your information from one region to some other and provision a copy of your core workload infrastructure. Resource required to back up information replication and fill-in such equally databases and object storage are e'er on. Other elements such as application servers are loaded with application code and configurations, simply are switched off and are just used during testing or when Disaster Recovery failover is invoked.
- Warm standby (RPO in seconds, RTO in minutes): Maintain a scaled-downward only fully functional version of your workload always running in the DR Region. Business-critical systems are fully duplicated and are always on, but with a scaled downwardly fleet. When the time comes for recovery, the system is scaled upward rapidly to handle the production load. The more scaled-up the Warm Standby is, the lower RTO and control airplane reliance will be. When scaled upwards to full calibration this is known as a Hot Standby.
- Multi-region (multi-site) active-agile (RPO near zippo, RTO potentially zero): Your workload is deployed to, and actively serving traffic from, multiple AWS Regions. This strategy requires you to synchronize information across Regions. Possible conflicts caused past writes to the same tape in two different regional replicas must be avoided or handled. Data replication is useful for data synchronization and will protect yous against some types of disaster, but it volition not protect yous against data corruption or devastation unless your solution also includes options for point-in-time recovery. Use services similar Amazon Route 53 or AWS Global Accelerator to route your user traffic to where your workload is healthy. For more than details on AWS services yous can use for active-active architectures see the AWS Regions section of Use Fault Isolation to Protect Your Workload.
Recommendation
The difference between Pilot Lite and Warm Standby can sometimes be difficult to understand. Both include an environment in your DR Region with copies of your primary region assets. The distinction is that Pilot Light cannot process requests without additional action taken first, while Warm Standby tin handle traffic (at reduced capacity levels) immediately. Airplane pilot Light will crave you to turn on servers, perchance deploy boosted (non-core) infrastructure, and scale upwards, while Warm Standby only requires you to scale up (everything is already deployed and running). Cull betwixt these based on your RTO and RPO needs.
Tips
Test disaster recovery implementation to validate the implementation: Regularly test failover to DR to ensure that RTO and RPO are met.
A pattern to avoid is developing recovery paths that are rarely executed. For example, you might accept a secondary data store that is used for read-only queries. When you write to a data shop and the primary fails, you lot might desire to fail over to the secondary data shop. If you don't frequently test this failover, yous might find that your assumptions near the capabilities of the secondary information store are incorrect. The capacity of the secondary, which might have been sufficient when you last tested, may exist no longer exist able to tolerate the load nether this scenario. Our feel has shown that the only error recovery that works is the path you test frequently. This is why having a small number of recovery paths is best. You can establish recovery patterns and regularly test them. If you have a complex or critical recovery path, you notwithstanding need to regularly execute that failure in production to convince yourself that the recovery path works. In the example nosotros just discussed, you lot should fail over to the standby regularly, regardless of need.
Manage configuration drift at the DR site or region: Ensure that your infrastructure, data, and configuration are as needed at the DR site or region. For case, bank check that AMIs and service quotas are upwards to date.
AWS Config continuously monitors and records your AWS resource configurations. It can notice migrate and trigger AWS Systems Manager Automation to gear up information technology and heighten alarms. AWS CloudFormation tin can additionally detect migrate in stacks you have deployed.
Automate recovery: Utilise AWS or third-political party tools to automate arrangement recovery and route traffic to the DR site or region.
Based on configured health checks, AWS services, such as Rubberband Load Balancing and AWS Machine Scaling, can distribute load to healthy Availability Zones while services, such as Amazon Road 53 and AWS Global Accelerator, tin route load to healthy AWS Regions.
For workloads on existing concrete or virtual data centers or private clouds CloudEndure Disaster Recovery, bachelor through AWS Marketplace, enables organizations to set up an automated disaster recovery strategy to AWS. CloudEndure also supports cross-region / cross-AZ disaster recovery in AWS.
Fast failover with Amazon Aurora PostgreSQL
Fast failover with Amazon Aurora PostgreSQL
There are several things you tin exercise to make a failover perform faster with Aurora PostgreSQL. This department discusses each of the post-obit ways:
- Aggressively gear up TCP keepalives to ensure that longer running queries that are waiting for a server response will be stopped before the read timeout expires in the consequence of a failure.
- Set the Java DNS caching timeouts aggressively to ensure the Aurora read-only endpoint tin properly cycle through read-only nodes on subsequent connection attempts.
- Set the timeout variables used in the JDBC connection string as low every bit possible. Utilize separate connection objects for short and long running queries.
- Use the provided read and write Aurora endpoints to plant a connexion to the cluster.
- Use RDS APIs to test application response on server side failures and utilise a bundle dropping tool to test awarding response for client-side failures.
Fast recovery after failover with cluster cache management for Aurora PostgreSQL
Fast recovery later failover with cluster cache management for Aurora PostgreSQL
For fast recovery of the writer DB instance in your Aurora PostgreSQL clusters if there'southward a failover, use cluster enshroud management for Amazon Aurora PostgreSQL. Cluster cache direction ensures that application performance is maintained if there's a failover.
In a typical failover situation, you might see a temporary simply large performance degradation after failover. This degradation occurs because when the failover DB instance starts, the buffer cache is empty. An empty cache is besides known as a cold cache. A cold cache degrades operation because the DB instance has to read from the slower disk, instead of taking advantage of values stored in the buffer enshroud.
With cluster cache direction, you set a specific reader DB case as the failover target. Cluster enshroud management ensures that the data in the designated reader's cache is kept synchronized with the data in the writer DB instance'south cache. The designated reader's cache with prefilled values is known as a warm cache. If a failover occurs, the designated reader uses values in its warm enshroud immediately when it'due south promoted to the new author DB case. This approach provides your awarding much better recovery performance.
Migration
Migrating data to an Amazon Aurora MySQL DB cluster
From Aurora cluster
Create clone
You are cloning an Aurora database. This volition create a new DB cluster that includes all of the data from the existing database likewise every bit a writer DB instance. To enable other accounts to clone this DB cluster, navigate to the DB cluster details page and share the cluster with other AWS accounts.
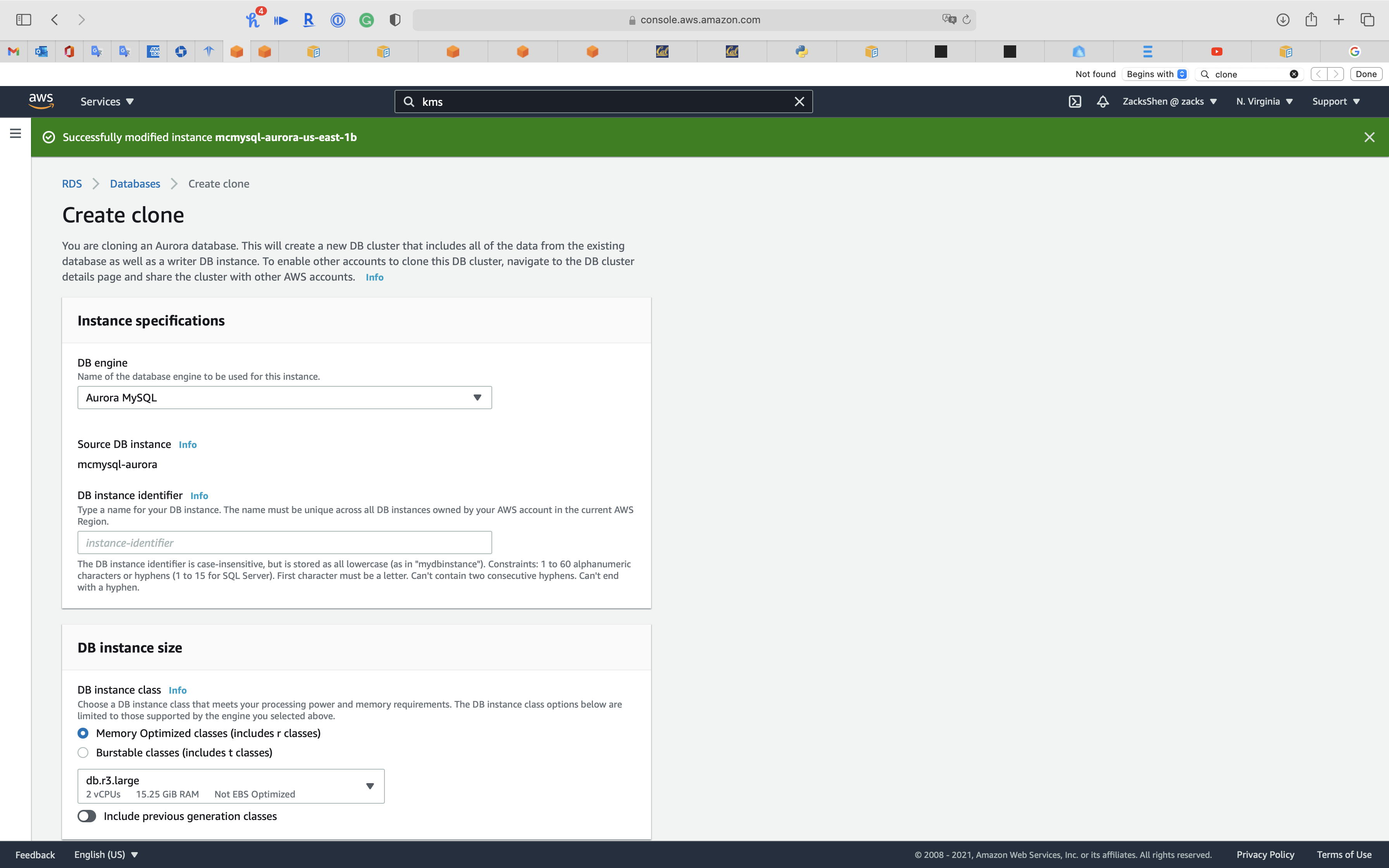
From RDS MySQL
Migrating information to an Amazon Aurora MySQL DB cluster
Migrating data from a MySQL DB case to an Amazon Aurora MySQL DB cluster by using an Aurora read replica
- Yous can drift from an RDS MySQL DB instance by offset creating an Aurora MySQL read replica of a MySQL DB instance.
- When the replica lag betwixt the MySQL DB instance and the Aurora MySQL read replica is 0, you can straight your client applications to read from the Aurora read replica and then stop replication to make the Aurora MySQL read replica a standalone Aurora MySQL DB cluster for reading and writing. For details, meet Migrating data from a MySQL DB instance to an Amazon Aurora MySQL DB cluster by using an Aurora read replica.
Select the RDS MySQL case y'all want to migrate.
Click on Action -> Create Aurora read replica
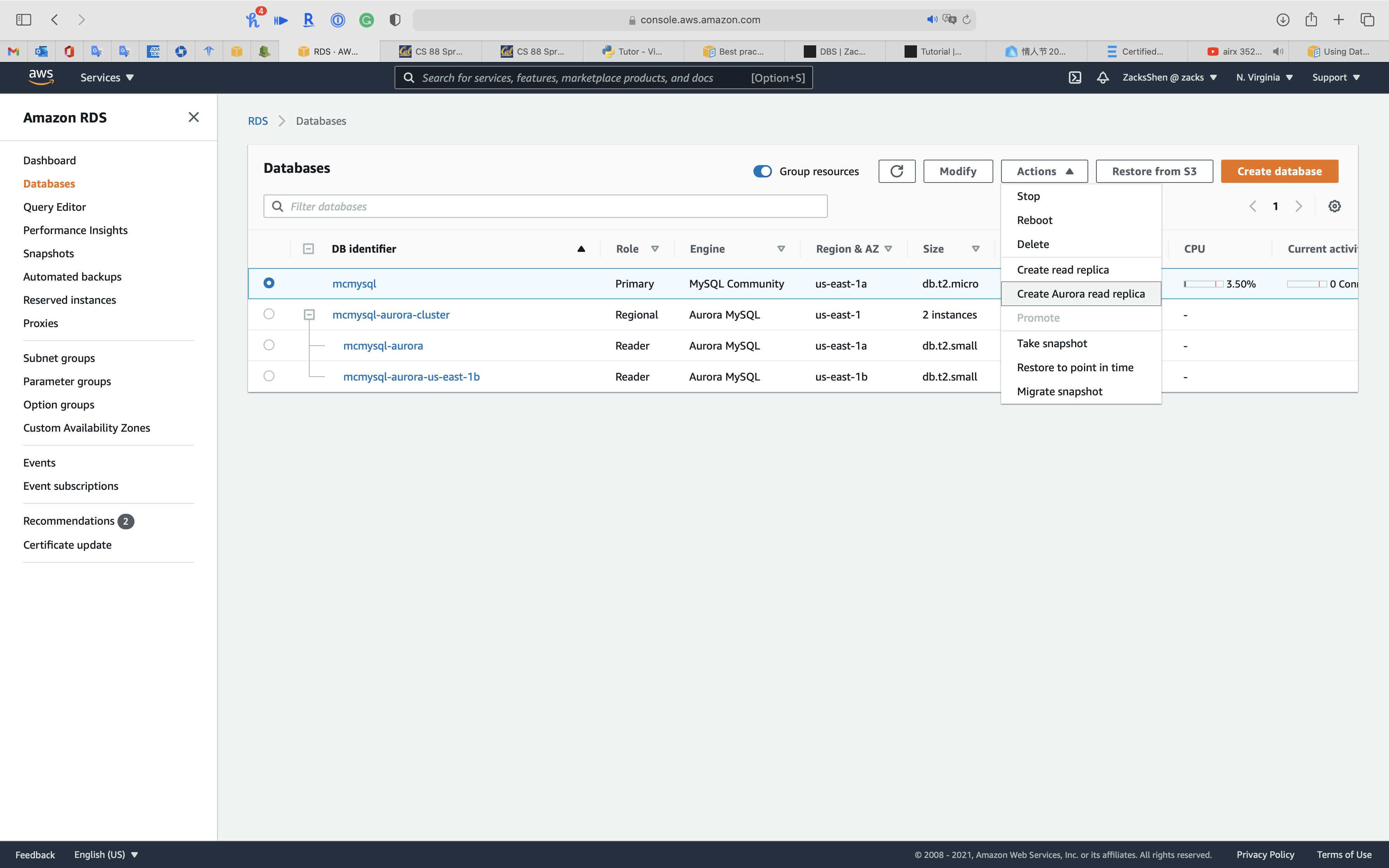
Configure the Aurora Read Replica Settings. meet Creating an Aurora read replica
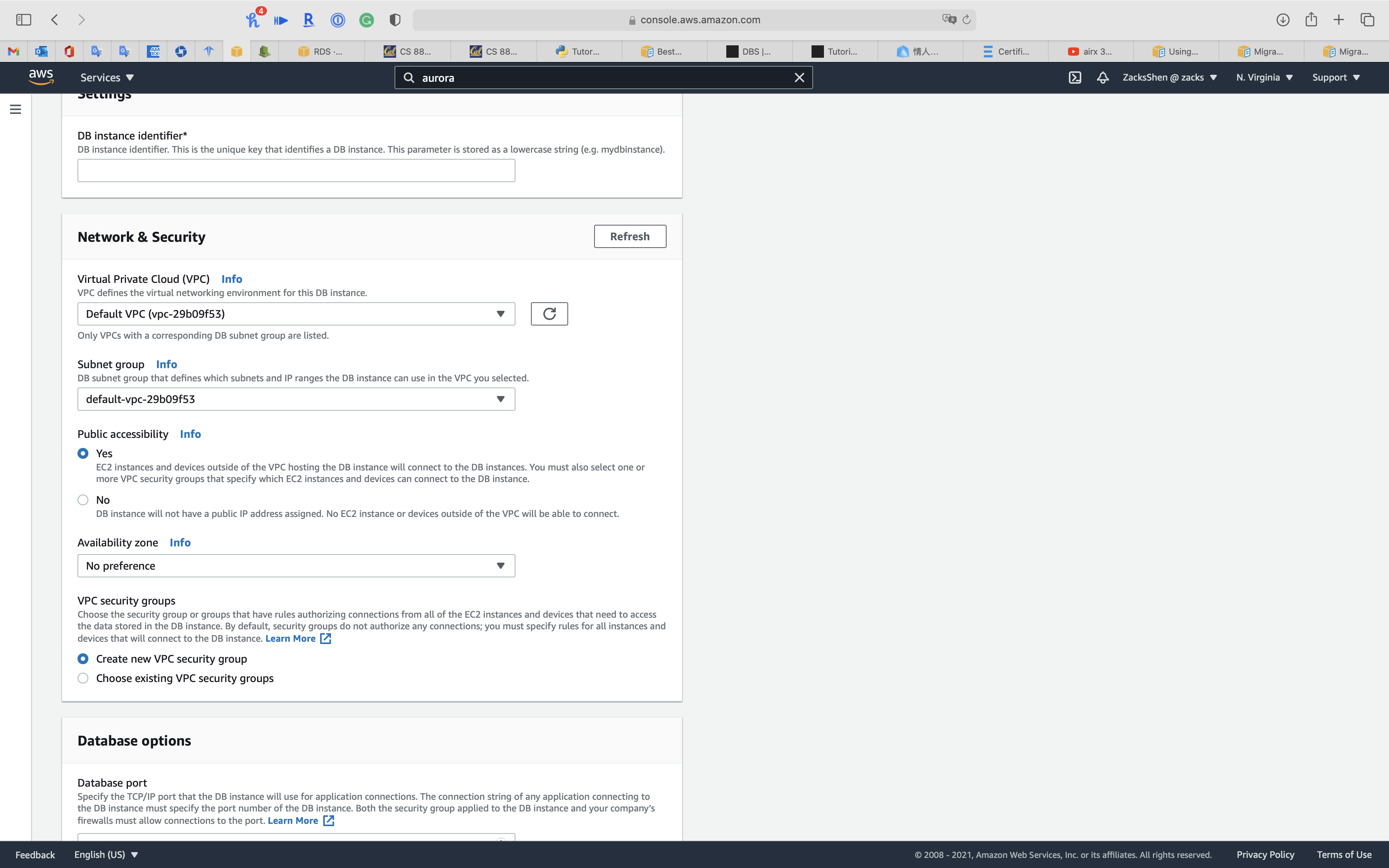
Meet condition of cluster is Modifying
See condition of cluster is Preparing-data-migration, wait several minutes.
When the status of cluster switches to Available, click on your cluster. See Promoting an Aurora read replica
Click on Activeness -> Promote
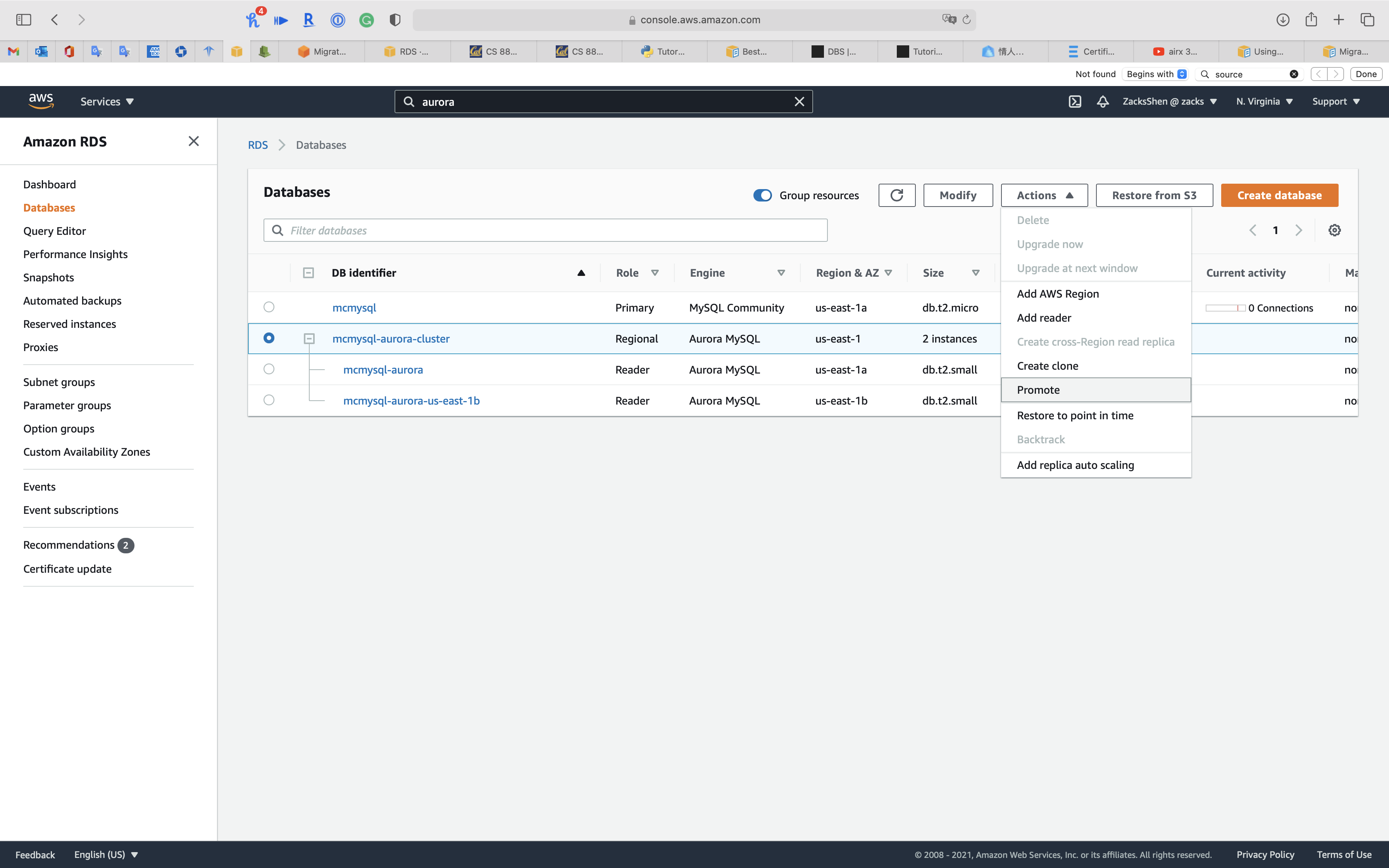
Before Promote
Click on Promote Read Replica
After Promote
You can also subscript an Event to confirm promote status
Service -> RDS -> Events
On the Events page, verify that at that place is a Promoted Read Replica cluster to a stand-solitary database cluster event for the cluster that yous promoted.
From RDS PostgreSQL
Migrating information to Amazon Aurora with PostgreSQL compatibility
To migrate from an Amazon RDS for PostgreSQL DB example to an Amazon Aurora PostgreSQL DB cluster.
- Create an Aurora Replica of your source PostgreSQL DB instance.
- When the replica lag between the PostgreSQL DB instance and the Aurora PostgreSQL Replica is zero, you can promote the Aurora Replica to exist a standalone Aurora PostgreSQL DB cluster.
Monitoring
Streaming Assay
Using Database Activity Streams with Amazon Aurora
Network prerequisites for Aurora MySQL Database Activity Streams
Prerequisite(part)
- For Aurora PostgreSQL, database activity streams are supported for version 2.3 or higher and versions three.0 or higher.
- For Aurora MySQL, database activity streams are supported for version ii.08 or college, which is uniform with MySQL version 5.7.
- You can first a database activity stream on the primary or secondary cluster of an Aurora global database.
- Database activity streams support the DB instance classes listed for Aurora in Supported DB engines for DB instance classes, with some exceptions:
- For Aurora PostgreSQL, you can't use streams with the db.t3.medium instance class.
- For Aurora MySQL, you lot can't use streams with whatever of the db.t2 or db.t3 instance classes.
Service -> RDS -> Databases
Select i node of your aurora cluster so click on Modify
Under DB case size
Select Memory Optimized classes (includes r classes) for powerful use case. Too, t series does not support Database Activeness Streams through Kinesis
Select db.r3.large
Click on Continue
Select Utilise immediately
Click on Alter DB instance
Select your cluster
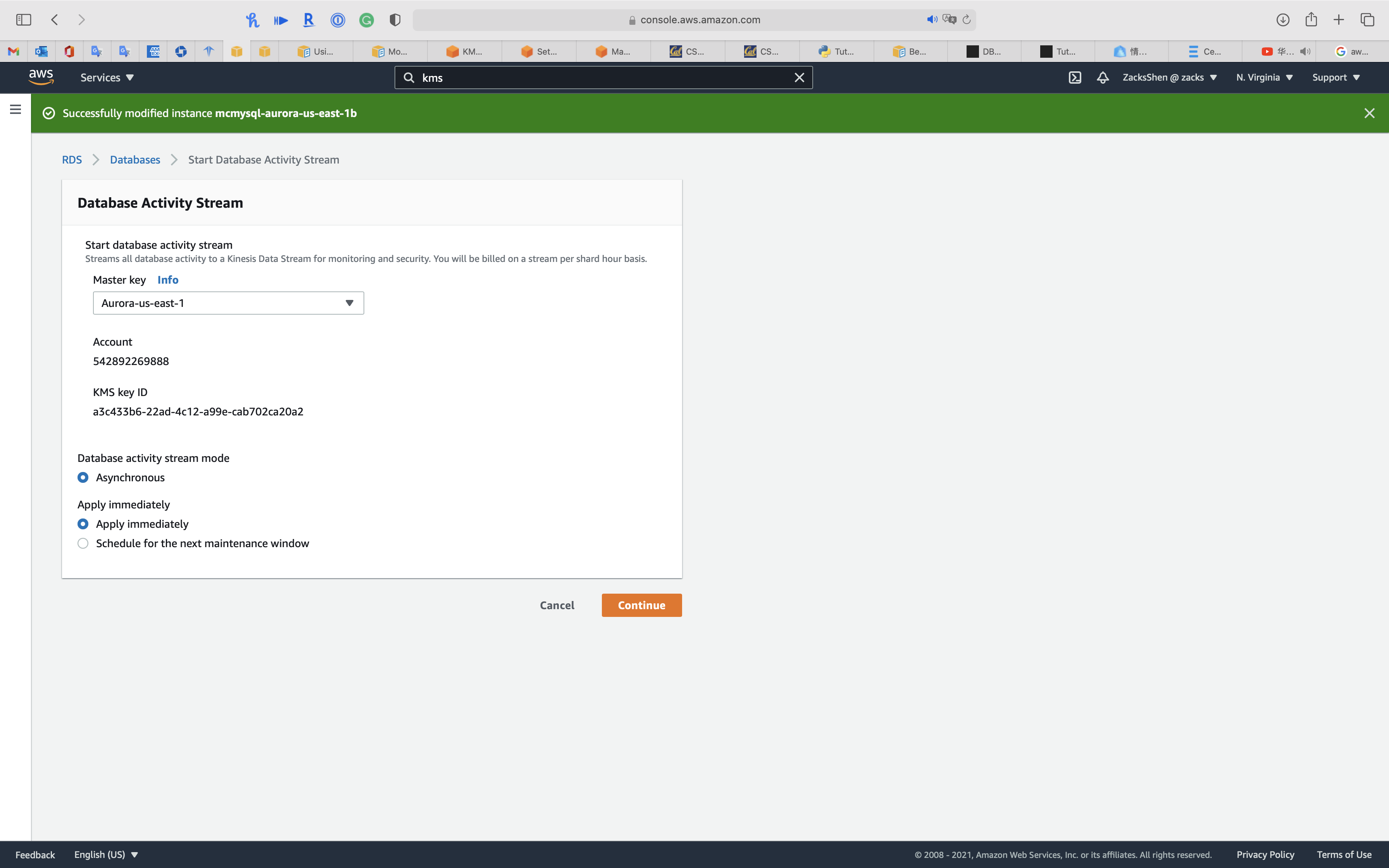
Click on Action -> Start activity stream
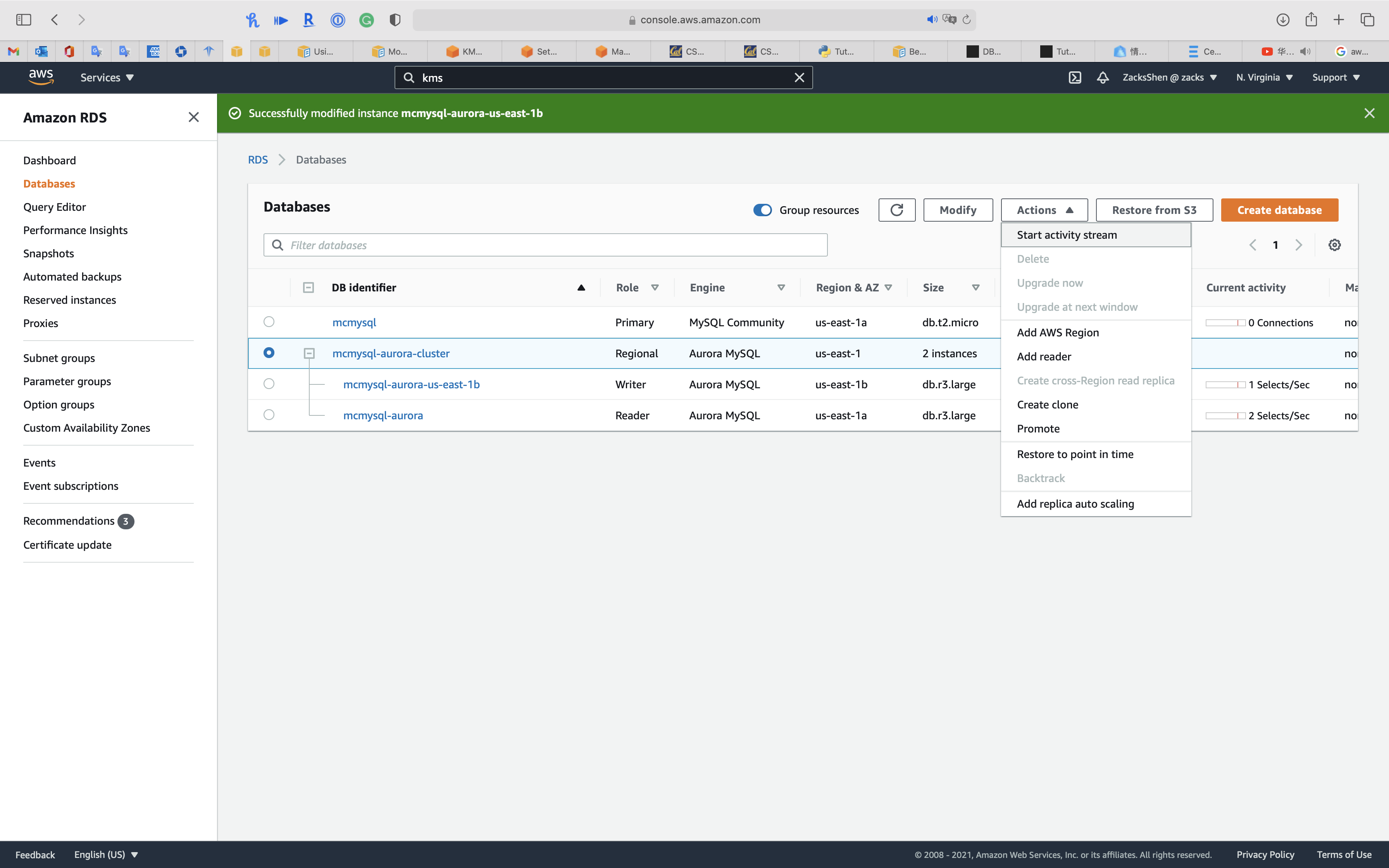
Select one of your KMS CMK
Select Apply immediately
Click on Keep
Click on your cluster
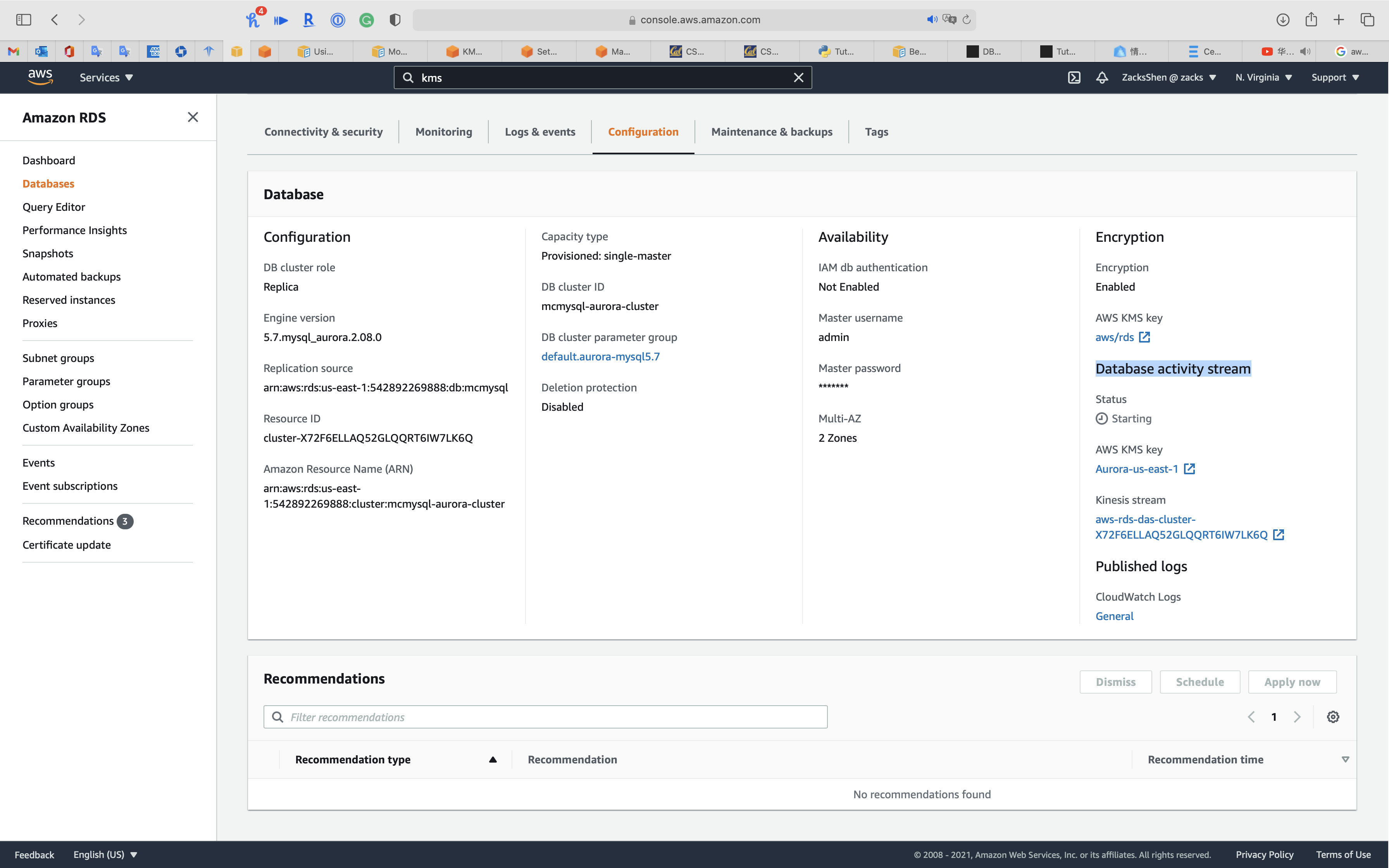
Click on Configuration tab
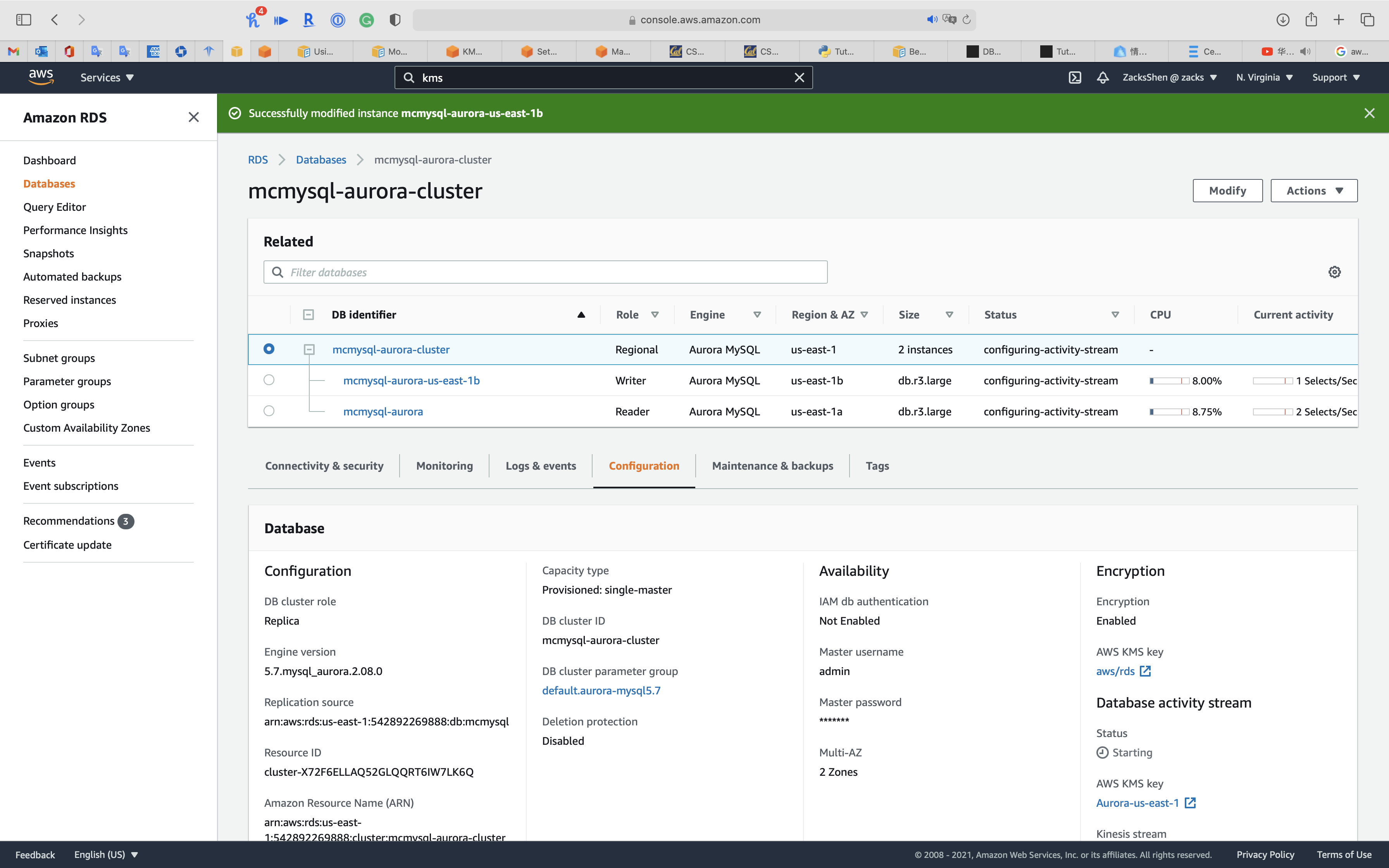
You can see Database activity stream and Kinesis stream
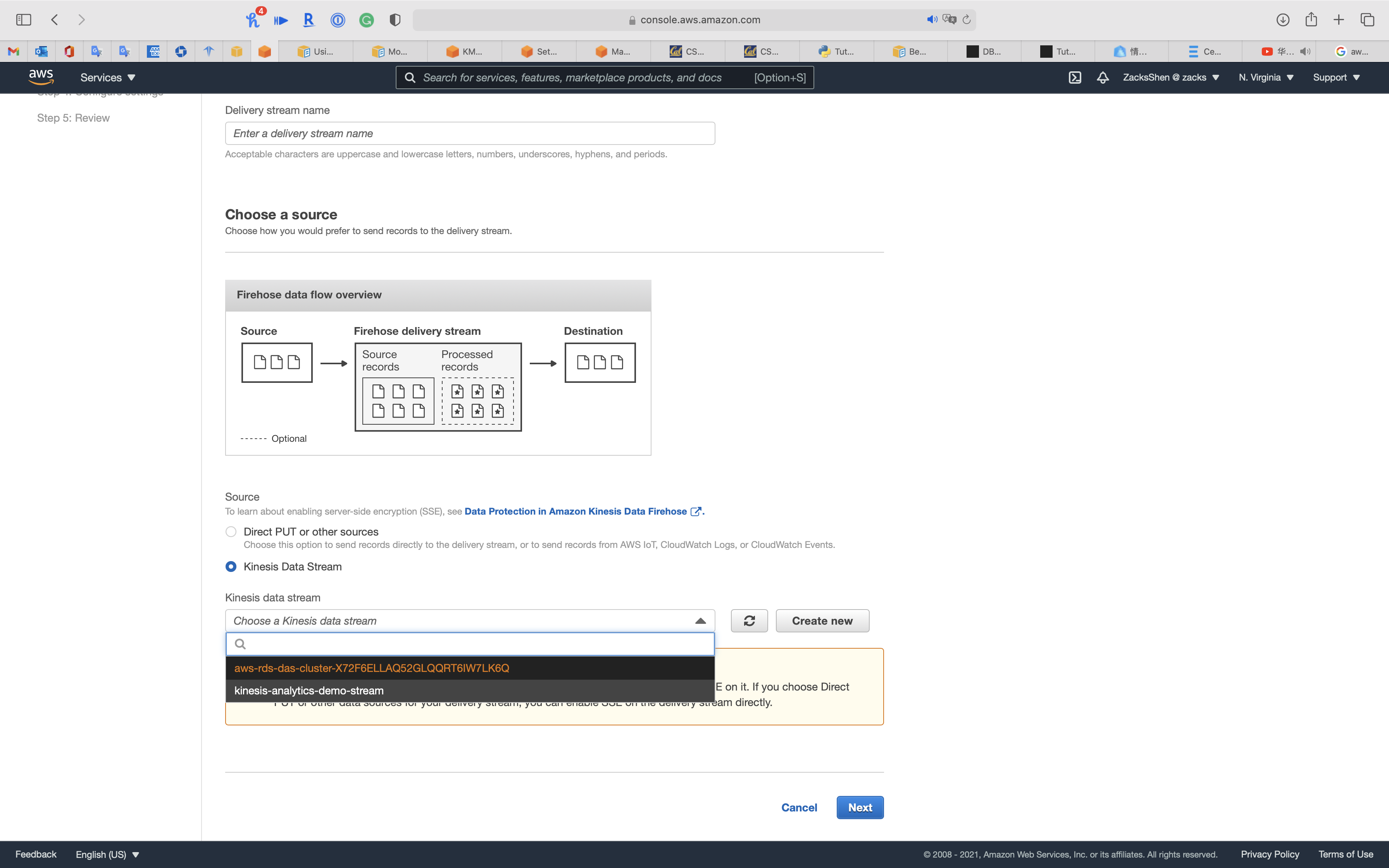
Service -> Kinesis -> Data Firehose
Once you create a Kinesis Data Firehose, yous tin can see your aurora cluster equally Kinesis Data Firehose source
Enhanced monitoring & Performance insights
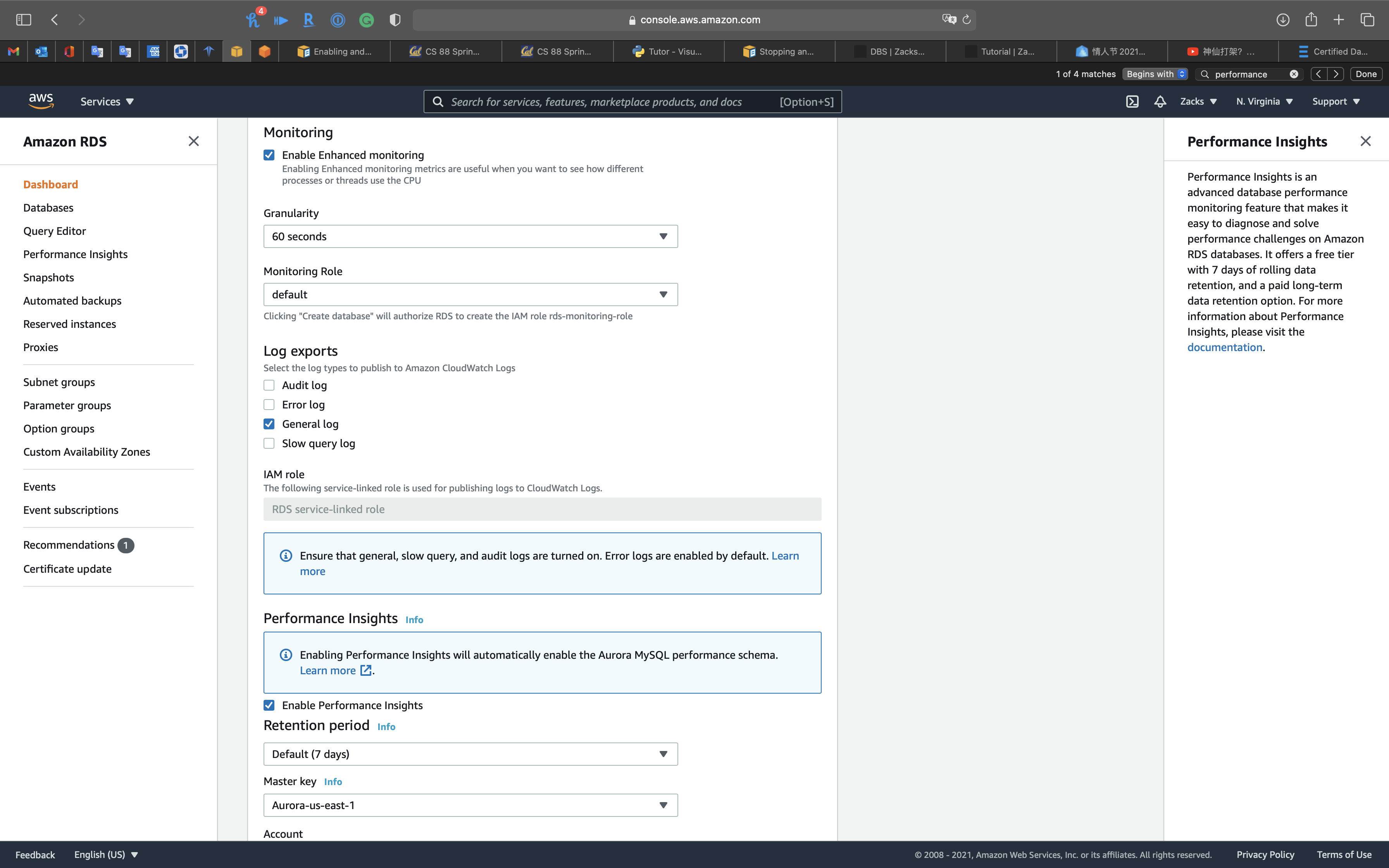
Enable Enhanced monitoring
Enabling Enhanced monitoring metrics are useful when you want to run into how dissimilar processes or threads use the CPU.
You can select Enable Enhanced monitoring function in the creating database flow or modifying database flow.
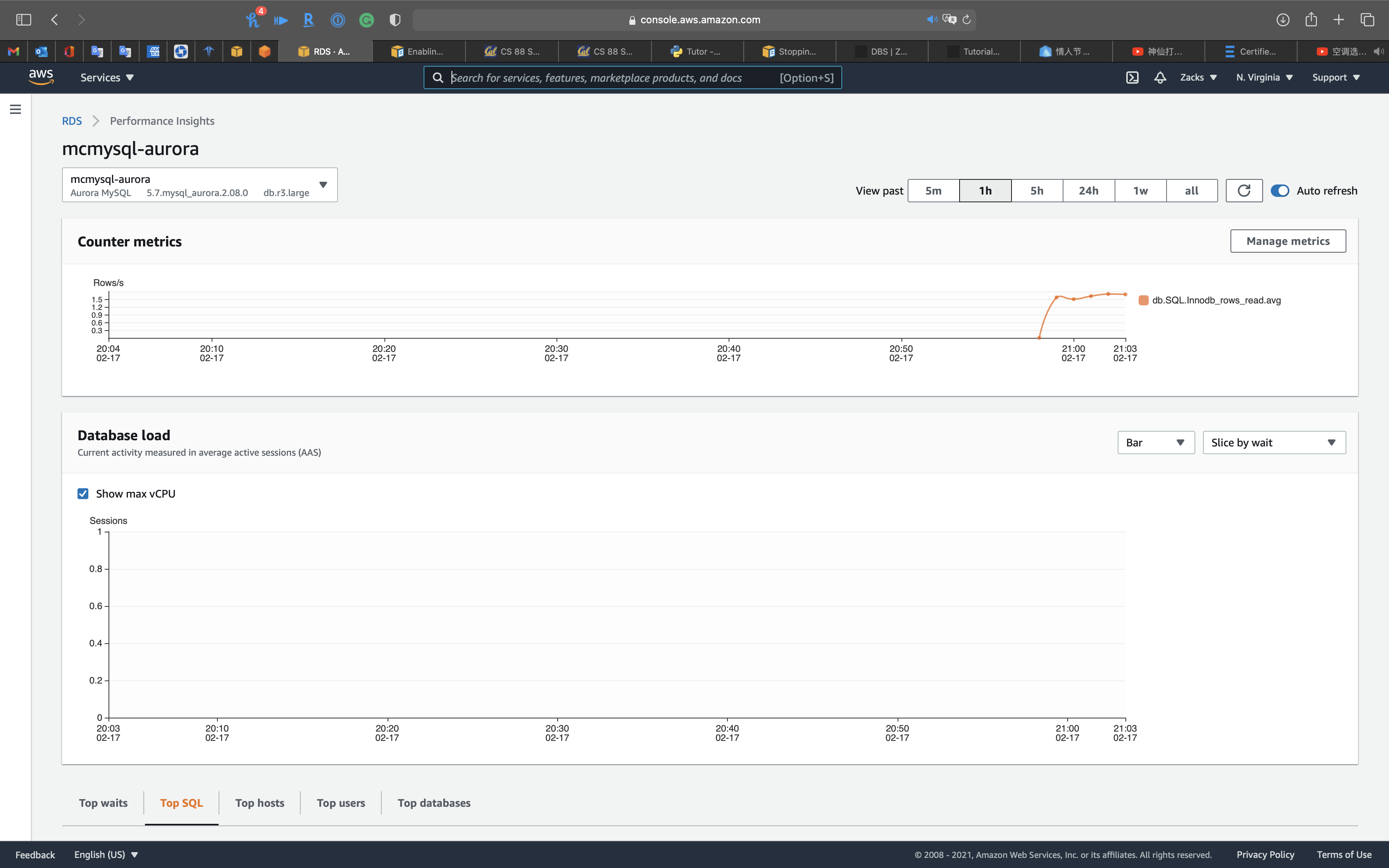
Functioning Insights
Performance Insights is an advanced database performance monitoring feature that makes it easy to diagnose and solve operation challenges on Amazon RDS databases. Information technology offers a free tier with 7 days of rolling information retention, and a paid long-term information retentiveness pick. For more information about Performance Insights, please visit the
CloudWatch
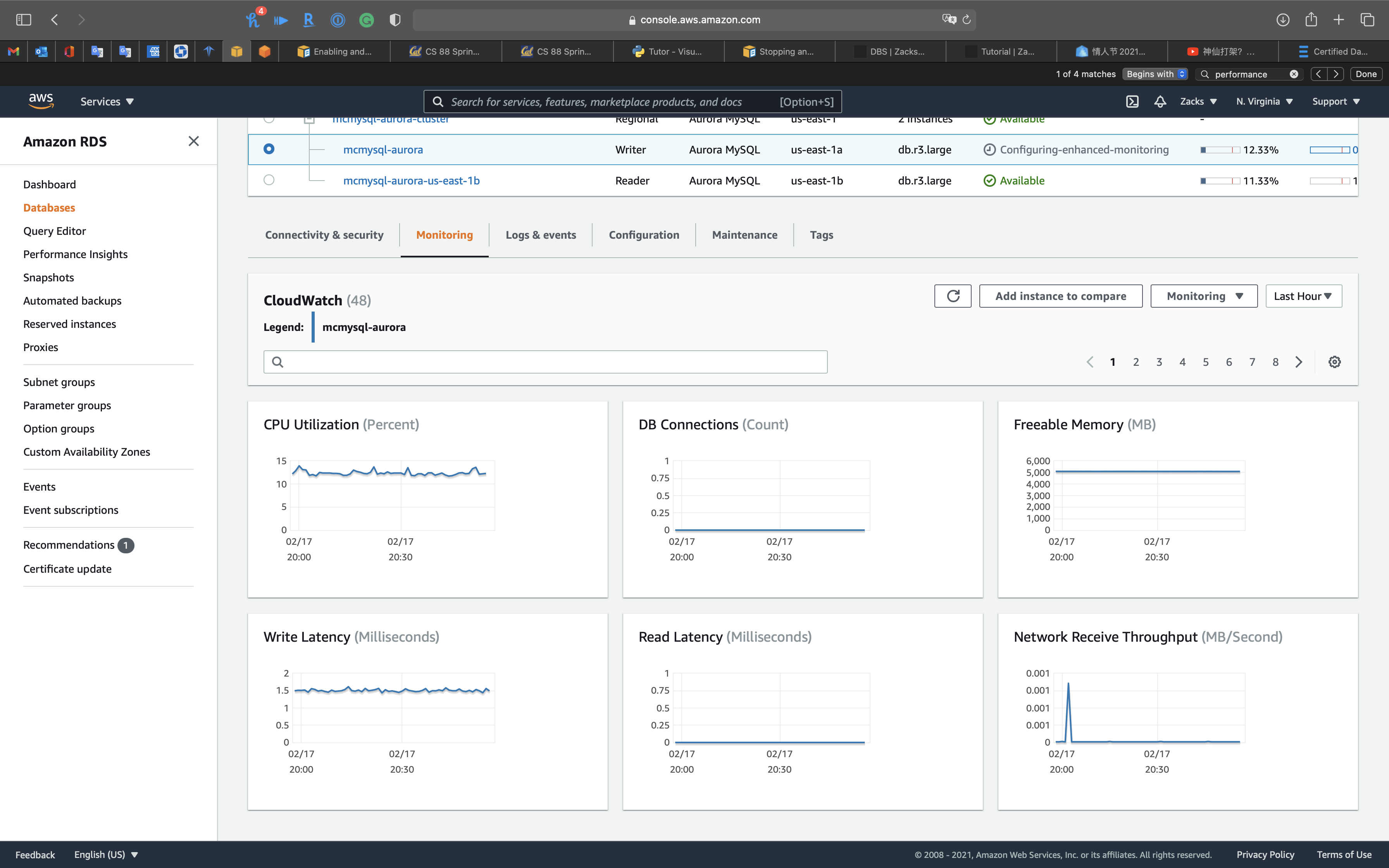
Enhanced monitoring
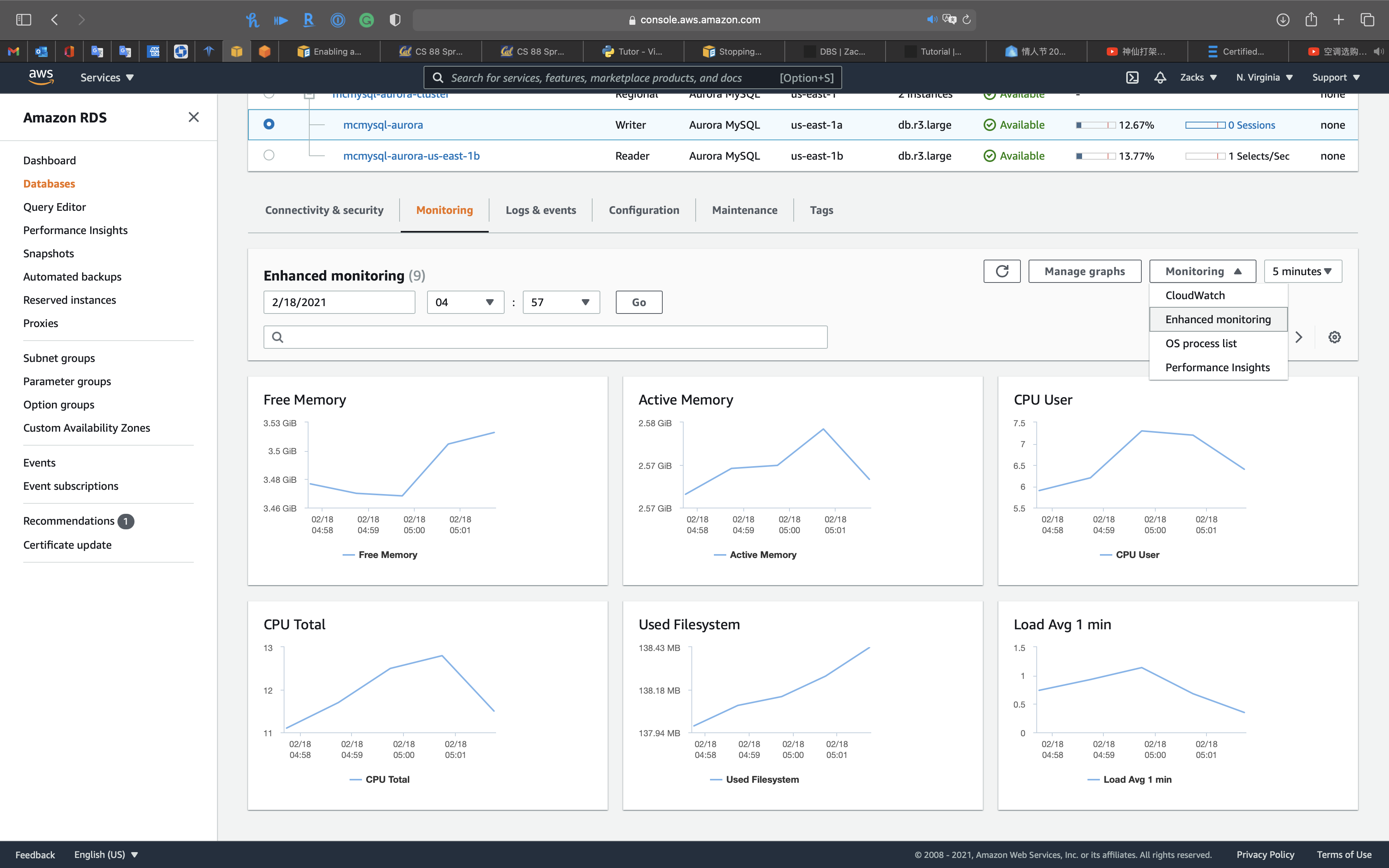
OS process list
Performance insights: y'all can review
- Top waits
- Top SQL
- Top hosts
- Summit users
- Superlative databases
Avant-garde Auditing with an Amazon Aurora MySQL DB cluster
Using advanced auditing with an Amazon Aurora MySQL DB cluster
Y'all tin can use the high-performance Advanced Auditing characteristic in Amazon Aurora MySQL to audit database activity. To do so, yous enable the collection of audit logs past setting several DB cluster parameters. When Advanced Auditing is enabled, yous can use it to log whatsoever combination of supported events. You can view or download the audit logs to review them.
server_audit_logging
Enables or disables Advanced Auditing. This parameter defaults to OFF; ready it to ON to enable Advanced Auditing.
server_audit_events
Contains the comma-delimited list of events to log. Events must be specified in all caps, and there should be no white infinite between the list elements, for example: CONNECT,QUERY_DDL. This parameter defaults to an empty cord.
You lot tin log any combination of the following events:
-
CONNECT– Logs both successful and failed connections and also disconnections. This event includes user information. -
QUERY– Logs all queries in plain text, including queries that neglect due to syntax or permission errors. -
QUERY_DCL– Similar to the QUERY result, but returns only information command linguistic communication (DCL) queries (GRANT, REVOKE, and so on). -
QUERY_DDL– Similar to the QUERY event, but returns but data definition language (DDL) queries (CREATE, Modify, and and then on). -
QUERY_DML– Like to the QUERY event, but returns only data manipulation linguistic communication (DML) queries (INSERT, UPDATE, and then on, and also SELECT). -
Tabular array– Logs the tables that were affected past query execution.
All-time Practices
Best practices with Amazon Aurora
This topic includes data on best practices and options for using or migrating information to an Amazon Aurora PostgreSQL DB cluster.
Bones operational guidelines for Amazon Aurora
Basic operational guidelines for Amazon Aurora
The following are basic operational guidelines that everyone should follow when working with Amazon Aurora. The Amazon RDS Service Level Agreement requires that you follow these guidelines:
- Monitor your memory, CPU, and storage usage. You tin gear up Amazon CloudWatch to notify you when usage patterns alter or when you approach the capacity of your deployment. This fashion, you tin maintain arrangement functioning and availability.
- If your customer application is caching the Domain Name Service (DNS) data of your DB instances, set a time-to-alive (TTL) value of less than 30 seconds. The underlying IP address of a DB instance can modify after a failover. Thus, caching the DNS data for an extended fourth dimension can pb to connectedness failures if your application tries to connect to an IP address that no longer is in service. Aurora DB clusters with multiple read replicas tin feel connection failures likewise when connections use the reader endpoint and one of the read replica instances is in maintenance or is deleted.
- Test failover for your DB cluster to sympathize how long the process takes for your use case. Testing failover can assist yous ensure that the application that accesses your DB cluster can automatically connect to the new DB cluster later failover.
Fast failover with Amazon Aurora PostgreSQL
Fast failover with Amazon Aurora PostgreSQL
At that place are several things y'all can practise to make a failover perform faster with Aurora PostgreSQL. This section discusses each of the following ways:
- Aggressively prepare TCP keepalives to ensure that longer running queries that are waiting for a server response volition exist stopped before the read timeout expires in the event of a failure.
- Prepare the Java DNS caching timeouts aggressively to ensure the Aurora read-just endpoint can properly cycle through read-simply nodes on subsequent connection attempts.
- Set the timeout variables used in the JDBC connection string equally low as possible. Use split connection objects for short and long running queries.
- Employ the provided read and write Aurora endpoints to institute a connection to the cluster.
- Use RDS APIs to test application response on server side failures and use a package dropping tool to test application response for client-side failures.
Aurora Serverless
Using Amazon Aurora Serverless v1
Using Amazon Aurora Serverless v2 (preview)
Amazon Aurora FAQs
Serverless is Aurora chapters selection other than Provisioned, which ways you cannot just enable or disable. You must Migrate your existing DB.
Q: Can I migrate an existing Aurora DB cluster to Aurora Serverless?
Yes, you can restore a snapshot taken from an existing Aurora provisioned cluster into an Aurora Serverless DB Cluster (and vice versa).
Amazon Aurora Serverless v1
Using Amazon Aurora Serverless v1
Use cases for Aurora Serverless v1
Aurora Serverless v1 is designed for the following utilise cases:
- Infrequently used applications – Y'all have an awarding that is merely used for a few minutes several times per day or week, such as a depression-volume blog site. With Aurora Serverless v1, you pay for merely the database resource that you consume on a per-second basis.
- New applications – Y'all're deploying a new awarding and yous're unsure about the instance size yous need. Past using Aurora Serverless v1, you can create a database endpoint and have the database autoscale to the capacity requirements of your awarding.
- Variable workloads – You lot're running a lightly used application, with peaks of xxx minutes to several hours a few times each twenty-four hours, or several times per year. Examples are applications for human being resources, budgeting, and operational reporting applications. With Aurora Serverless v1, you no longer need to provision for tiptop or boilerplate chapters.
- Unpredictable workloads – You're running daily workloads that have sudden and unpredictable increases in activity. An instance is a traffic site that sees a surge of activeness when it starts raining. With Aurora Serverless v1, your database autoscales capacity to meet the needs of the application's meridian load and scales back downwards when the surge of activeness is over.
- Development and test databases – Your developers use databases during piece of work hours only don't need them on nights or weekends. With Aurora Serverless v1, your database automatically shuts downward when it's non in utilise.
- Multi-tenant applications – With Aurora Serverless v1, yous don't take to individually manage database capacity for each application in your fleet. Aurora Serverless v1 manages individual database capacity for you.
Troubleshooting for Aurora
Troubleshooting for Aurora
No space left on device
You might encounter one of the post-obit fault letters.
- From Amazon Aurora MySQL:
ERROR 3 (HY000): Fault writing file '/rdsdbdata/tmp/XXXXXXXX' (Errcode: 28 - No infinite left on device) - From Amazon Aurora PostgreSQL:
Mistake: could not write block XXXXXXXX of temporary file: No space left on device.
Each DB case in an Amazon Aurora DB cluster uses local solid state drive (SSD) storage to store temporary tables for a session. This local storage for temporary tables doesn't automatically grow like the Aurora cluster volume. Instead, the amount of local storage is limited. The limit is based on the DB instance grade for DB instances in your DB cluster.
To show the amount of storage available for temporary tables and logs, you tin can use the CloudWatch metric FreeLocalStorage. This metric is for per-case temporary volumes, not the cluster book. For more than information on bachelor metrics, see Monitoring Amazon Aurora metrics with Amazon CloudWatch.
In some cases, y'all can't alter your workload to reduce the amount temporary storage required. If and then, change your DB instances to use a DB instance course that has more local SSD storage. For more information, see DB instance classes.
Source: https://zacks.one/aws-aurora/
0 Response to "Rds Mysql Read Replica Not Clearing Temp"
Post a Comment